Maintaining Privacy With Agents: What Actually Works When Sensitive Data Is Part of the Workflow
Maintaining Privacy With Agents: What Actually Works When Sensitive Data Is Part of the Workflow
The practical privacy question for agent systems is whether an agent harness exposes reliable control points before model-visible context is assembled, and whether those control points are strong enough to support more than a binary allow-or-block policy. This is important because mixed-sensitivity workflows are common: useful and sensitive content are often intertwined, and a privacy layer that only knows how to stop work is not a usable answer.
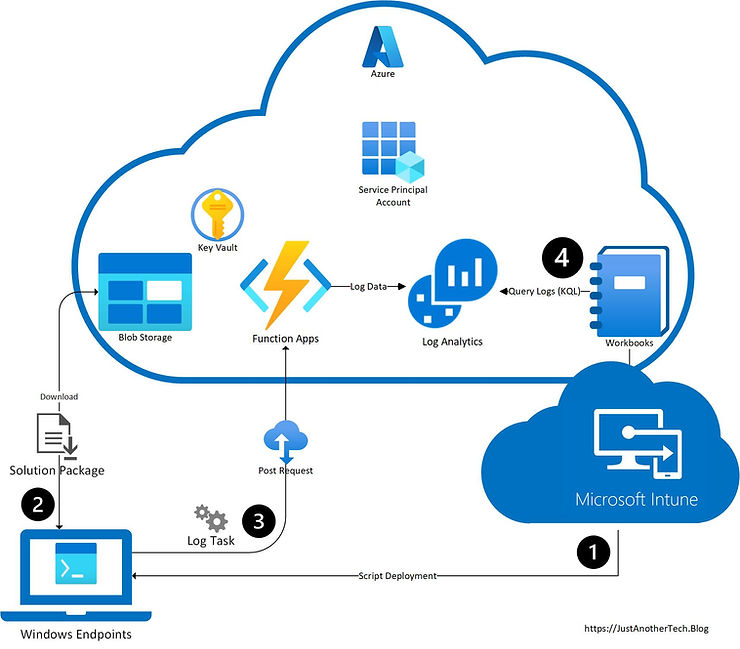
The repository I am releasing, agent-privacy, came out of exploring that problem across multiple agent harnesses. Privacy can be improved materially when the system treats information flow as the primary problem, models harness differences explicitly, and routes content through more than one outcome. The design that emerged from that work is built around four actions — allow, redact, handoff, and block — because anything simpler proved either too weak or too disruptive.
Scope
This is not a general survey of AI privacy. It is an exploration of privacy controls for CLI-style agent harnesses that can read files, run shell commands, call tools, and re-inject those results into the next model turn. The central question is where sensitive data can still be intercepted before it becomes model-visible context, and what kinds of control those interception points actually support in live behavior.
This question sits in the middle zone that much privacy advice skips. “Never use sensitive data” and “scrub everything first” are both cleaner than dealing with a prompt that is mostly safe except for one identifier, a tool result that contains the answer plus a customer reference, or shell output that is operationally useful but not clean enough to pass through unchanged. The project treats privacy as an information-flow problem: where does new information enter the harness, what sees it next, and what can still be altered before it reaches the model?
How I evaluated it
The core method was iterative implementation and live testing across harnesses. I wired up prompt hooks, pre-tool hooks, and post-tool hooks, then tested what actually passed through, what could be blocked, what could be replaced, and what only produced advisory behavior. Several of the most important differences only became obvious in live turns, after tool execution, or under failure conditions.
That testing work shaped the implementation itself. It included building the local filter service, evaluating OpenAI Privacy Filter as the contextual PII layer, integrating local Qwen models for fallback or pass-through behavior, and separating the shared privacy logic from the harness-specific adapters. Privacy Filter was a useful model to evaluate in this role because it is built to scan unstructured text, identify sensitive items like names or account numbers, and mask them in one pass, while still using surrounding context to make better decisions than regex alone. It is also designed to run locally. Each time a harness exposed a weaker control surface, an ambiguous contract, or a gap between synthetic and live behavior, the design had to adapt around that reality.
I also used the repository’s own operational artifacts as evidence. The current pii-guard report window covers activity from mid-May through mid-June 2026 and records 6,343 screening decisions, including action counts, event distributions, scanner activity, degraded states, and latency characteristics.
I compared the live behavior of Claude Code, GitHub Copilot CLI, and Codex CLI within this system. The comparison focused on which interception points actually worked for privacy, what payload they exposed, whether they supported denial, replacement, annotation, or handoff, and how those behaviors changed under degradation or unsupported paths.
Finding 1: feature parity is overstated; the real unit is the harness contract
The first large finding is that “supports hooks” is not a meaningful privacy claim by itself. Hooks are general-purpose harness features. They can be used for notifications, logging, workflow control, approvals, and many other behaviors that have nothing to do with privacy. I focused on which hooks became meaningful privacy control points, and how much control they actually provide once privacy is the use case. The hook-exposed intervention surfaces are prompt hooks, pre-tool hooks, and post-tool hooks. Permission-request events govern whether risky tool actions proceed and are distinct from interception or replacement of model-visible content.
Claude Code has the broadest hook surface. Copilot CLI exposes fewer major hook events, but some of its most important pre-tool behavior is operationally stronger because command-based preToolUse fails closed. Codex is the most constrained of the three for transformation-style privacy controls: denial is more trustworthy than substitution, and response shapes that imply rewriting or replacement do not necessarily become live enforcement behavior.
| Harness | Hook Surface | Pre-tool Behavior | Post-tool Replacement | Key Constraint |
|---|---|---|---|---|
| Claude Code | Broadest | Fail-open unless exit code set correctly | Supported | Requires exit-code discipline to enforce |
| Copilot CLI | Fewer events | Stronger – command-based preToolUse fails closed |
Limited annotation | Smaller hook surface overall |
| Codex CLI | Most constrained | Limited | Not reliably enforced | Response shapes don’t become live enforcement |
This is more than naming drift. It changes what kind of privacy layer is even possible. A shared detector can classify the same content the same way across harnesses. A shared policy can decide that some result should be redacted before the model sees it. But if one harness supports genuine output replacement, another supports denial plus limited annotation, and a third only supports a subset of those controls reliably, then the privacy story is being determined by the harness contract, not by the detector alone.
That is why the architecture in agent-privacy split into shared policy and thin harness-specific adapters. It was the only way to keep the implementation honest while the surfaces converge faster than their behavior does.
Finding 2: the highest-value interception point is usually the transit leg, not the prompt hook
Prompt hooks are useful, but the most important privacy control in these systems is usually the point where tool output is in transit back to the model but has not yet been reintroduced into context.
Prompt hooks are conceptually simple: a user types something sensitive, the harness intercepts it, and the system blocks or rewrites it. That matters for pasted secrets or obvious identifiers. But prompt hooks only see the raw user prompt. They do not see the assembled turn, the results of a file read, the output of a shell command, or the payload returned by an external tool. Those later surfaces are where much of the actual privacy risk accumulates.
Post-tool interception matters because it sits on the transit leg between tool execution and the next model call. If the harness supports true replacement of the model-facing result, then a redacted or summarized version can be what the model sees next rather than the original. If the harness only supports annotation, warning text, or advisory context alongside the original result, then the privacy control is weaker than it looks because the raw content is still in circulation.
That distinction became a design rule in the repository. additionalContext-style behavior is treated as explanatory only. Replacement fields are treated as the actual privacy control where the harness supports them. Where a harness does not support real replacement reliably, the safer posture is to block or downgrade to ensure the content has been contained.
Finding 3: a usable privacy layer needs more than allow and block
The next major finding is about outcome design rather than hook mechanics. The system needs more than a gate; it needs routing.
An allow-or-block design is too coarse for mixed-sensitivity work. If a document, prompt, or tool result is mostly useful with a few sensitive spans, blocking it destroys value that could have been preserved. But allowing it through untouched defeats the point of the privacy layer. Redaction solves part of that problem by preserving structure while removing the risky details. It keeps the workflow moving when the sensitive content is important enough to remove but not so central that removing it destroys the task.
Redaction, however, is not the whole answer. Some tasks depend on the raw content for reasoning. A tax-style workflow, a financial record comparison, or a personally identifying support artifact may be too sensitive for the public path but too semantically dense to survive useful redaction. That is where handoff becomes necessary.
Handoff changes the role of the privacy layer from simple gating to routing. Instead of treating “too sensitive for the default path” as equivalent to “stop the work,” the system sends the raw content to a private local path and returns a narrower result that is safe enough for the broader workflow. In the current implementation, the hook process itself acts as the broker: it calls the local backend, waits for the response, and then returns a normal hook response containing only a minimal structured result — summary, actionable details if needed, and a note about withheld categories when relevant — rather than mirroring the sensitive source content back into the main workflow. In the current state of local models, this is most useful for summarization, extraction, and returning the specific information needed to continue the task. It is less effective for more complex reasoning, where a local handoff may still require manual takeover or a stronger frontier-model path. In that sense, handoff does not remove the capability gap between local and frontier models; it changes where sensitive reasoning happens and what can be safely returned from it.
This also narrows the project’s privacy claim. The goal is not to make raw sensitive data disappear from every possible process. The goal is to keep that raw detail off the broader path when it does not need to be there.
| Outcome | When applied | What happens | Tradeoff |
|---|---|---|---|
| Allow | Content is clean | Passes through unchanged | None |
| Redact | Mixed-sensitivity, structure preservable | Sensitive spans removed, workflow continues | Some detail lost |
| Handoff | Raw reasoning needed, too sensitive for public path | Sent to local model; safe summary returned | Bounded by local model capability |
| Block | High-risk content or unsupported harness path | Content stopped | Work interrupted |
Finding 4: selective routing needs both contextual filtering and deterministic coverage
Another large finding is that the contextual filter service is often the more capable and scalable way to detect sensitive content in mixed real-world text, but it is still not sufficient as the only control layer or as the place every surface should be routed through. A service-based model can outperform brittle deterministic matching in many cases because it does not depend on anticipating every pattern in advance. At the same time, exhaustive routing would add cost, latency, and noise in places where the privacy value is low. That is part of why the project converged on CRUD-aware gating (Create, Read, Update, Delete – the four basic categories of operations an agent can perform on data): prioritize the read and ingress paths where new model-visible information is actually entering the system, and avoid treating every operation as if it deserves the same level of inspection. That selective focus is also consistent with broader agent-trajectory evidence. In the Mini-SWE-Agent GPT-5.4 trajectory analysis paper (arXiv:2606.14066v1), reading and searching accounted for 56.2% of tool-use turns and 46.5% of the main agent’s token share. That supports the narrower point that read-heavy surfaces absorb a disproportionate share of agent attention, which makes them high-value places to focus CRUD-aware privacy controls and model-visible risk reduction. In practice, deterministic controls remained necessary not as the primary detector, but as complementary coverage alongside the service.
In this project, I combined my research with OpenAI Privacy Filter - it is built to identify and mask PII spans in unstructured text, with a label taxonomy that covers categories like person, address, email, phone, date, URL, account number, and secret. That makes it much more useful for mixed real-world content than regex alone. It helps with partial addresses, names in context, mixed conversational text, and many of the cases where trying to enumerate every pattern manually becomes brittle or incomplete. Other models and frameworks can help with the same class of problem; this is the one I evaluated in this implementation. But deterministic controls still matter. In the current implementation they serve several narrower roles: cheap front-door triage before deeper routing, always-on handling for some high-confidence high-risk patterns, and degraded-mode protection when the richer service path is unavailable. Its model card is also explicit that it is a data-minimization aid rather than a blanket privacy guarantee.
The architecture converged on a two-tier model with selective routing. Contextual filtering does much of the heavy lifting where mixed and ambiguous content is involved, but in this project that filtering still runs within the local environment through a local or LAN-hosted service. Deterministic screening remains in place as complementary coverage: it provides in-process triage, explicit handling for some known high-risk patterns, and degraded-mode protection when the filtering service is unavailable. CRUD-aware gating limits where deeper inspection is applied. That design was not just about accuracy. It was also about operational fit. A privacy layer that routes every surface through even a local service path is not a usable one; a layer with no secondary safeguards or degraded-mode protection is not a strong one.
| Tier | Mechanism | Strengths | Role in this project |
|---|---|---|---|
| Contextual | Service-based filter (Privacy Filter) | Handles mixed/ambiguous text, names in context, partial addresses | Primary detection for complex real-world content |
| Deterministic | Pattern matching / regex | Fast, always-on, no external call | Front-door triage, high-confidence patterns, degraded-mode fallback |
Finding 5: live behavior matters more than isolated hook tests
The evaluation method matters almost as much as the implementation. An agent hook returning the right JSON in a direct test does not demonstrate that the harness honors that response at the right time, under the same semantics, and in a real turn.
That gap between synthetic success and live enforcement created a lot of early false confidence. A script can print a block response beautifully and still fail to prevent model-visible exposure if the harness ignores that shape, treats it as advisory, or applies it later than expected. Likewise, there were leaks where post-tool hooks appeared to “redact” output while still allowing the original content to remain part of the next model turn where the harness only appends context (option likey meant for auditing) rather than replacing the result.
For that reason, when using agent hooks, do not just evaluate “did the hook run?”, but “what did the harness actually pass through next?” The project documentation distinguishes sharply between replacement, annotation, denial, and handoff rather than discussing them as if they were interchangeable forms of screening.
Design implications in agent-privacy
The implementation that came out of those findings has three architectural properties that matter.
The first is a strict split between shared policy and harness-specific enforcement. The repository keeps classification, redaction logic, secrets scanning, injection screening, and audit semantics in shared code. The harness adapters stay thin and translate those decisions into whatever the harness actually supports. This keeps the project from over-abstracting the very differences that determine whether a privacy control is real.
The second is a four-outcome decision model. Clean content is allowed to continue. Mixed-sensitivity content is redacted when useful structure can be preserved. Content that still requires raw reasoning is handed off to a private local path. High-risk or unsupported cases are blocked. In the current state of local models, that handoff path is especially useful when it can retrieve, summarize, or extract what is needed and hand back a result that lets the workflow continue on a stronger frontier model when necessary. The implementation makes that boundary explicit by prompting the local backend to return a minimal safe result and then shaping the reply into a summary, actionable details, and withheld note before it is returned to the harness. This is more complicated than a gate, but the complexity is doing real work: it preserves utility where possible and refuses to pretend that one action fits every privacy case. The implementation also distributes responsibility across stages: contextual filtering for ambiguous content, deterministic checks for high-confidence or degraded cases, and routing logic for deciding when deeper inspection is worth the cost.
The third is an audit-first posture. Every hook invocation records a decision trail without persisting raw content. That does not itself provide privacy, but it does make the layer observable enough to reason about false positives, degraded states, harness-specific behavior, and latency tradeoffs. Without that, the system would be much harder to tune honestly.
Evidence from the current report window
The report data supports the argument that this layer is operating as a routing system rather than a blunt blocker.
Across 6,343 recorded decisions, 4,456 (70%) were allows, 909 (14%) were blocks, 658 (10%) were redactions, and 320 (5%) were warnings. That mix matters. It shows that the project is not structured around denial as the default answer. Most traffic continues normally. At the same time, there is enough redaction activity to show that the system is preserving workflow value in cases that would otherwise collapse into either over-sharing or hard blocking.
The event distribution reinforces the earlier finding about interception points. The report records 3,567 (56%) post-bash events, 1,792 (28%) prompt events, and 977 (15%) pre-bash events. The busiest surface is the one closest to tool output re-entry, not the original user prompt. That is exactly what the broader argument would predict: once tools and shell commands are in play, the transit leg becomes the main place where mixed-sensitivity content has to be handled.
The harness-level numbers are also directionally useful. Copilot shows a higher block rate than Claude or Codex in the current data, while Codex shows comparatively less blocking and more reliance on warning or redaction-adjacent behavior. Those numbers should not be read as benchmark claims about the harnesses overall. They partly reflect which harness was in active use during the report window – a harness used more frequently will simply accumulate more events. They are observations about how the privacy layer behaves inside their respective contracts, not a controlled comparison of harness behavior under equal workloads.
Latency is where the operational cost becomes most visible. Prompt checks remain very fast, with a 2.8 ms p50. Pre-command checks remain similarly small at 6.6 ms p50. The median post-tool path is still workable at 40.8 ms, but the long tail is significant: post-tool p95 reaches 7.1 seconds. That long tail matters because a privacy layer that is too slow becomes easier to bypass socially even if it remains technically correct.
Limits
The findings above do not amount to total containment.
Hooks do not expose the fully assembled outbound provider request. Process environment remains a separate category of risk from prompt text or tool output. Some secondary paths — including subagent behavior and context compaction — are weaker, later, or more harness-specific than a clean conceptual model would suggest. And even where interception exists, the harness may support annotation more strongly than substitution.
That is why this project treats hooks as a strong layer in a defense-in-depth design rather than as the whole boundary. The system can reduce unnecessary exposure materially. It can make key control points visible and enforceable. It can keep a meaningful amount of mixed-sensitivity work on a safer path. But if the requirement is a hard trust boundary on every outbound payload, the solution space extends beyond hooks into proxies, isolation, and stricter execution designs.
What the repository contributes
The repository of work doesn’t solve for all agent privacy concerns, but offers in-built methods for effectively handling the majority of use cases. It treats information flow as the central privacy problem. It treats harness contracts as first-class implementation constraints. It treats post-tool replacement differently from annotation. It treats handoff as a core action rather than an admission of failure. And it treats deterministic local controls as the floor underneath any richer filtering model.
Those are the core contributions. The repository gives practicioners and researchers something concrete to inspect, test, and evaluate for themselves. The write-up explains how the project comes together.
Conclusion
Privacy in agent workflows improves when the system is designed around real harness control points, when it distinguishes replacement from annotation, and when it routes content through more than one outcome.
Allow and block are not enough for mixed-sensitivity work. Redaction is necessary but not sufficient. Handoff closes the gap between a privacy control that interrupts useful work and a privacy control that can keep the work moving while changing where the raw detail is allowed to travel.